
Tag: Portfolio
-

Presentation at GAFFTA Creative Code Meetup VII
I gave a talk at the GAFFTA Creative Code Meetup back in November. It was a brief overview of my recent work including Zen Photon Garden, High Quality Zen, the Ardent Mobile Cloud Platform, and Fadecandy. It includes a live demo of Fadecandy, starting at 18:43. Creative Code Meetup VII- Micah Elizabeth Scott from GAFFTA…
-

Fadecandy: Easier, tastier, and more creative LED art
I’ve been working on a project lately that I’m really eager to share with the world: A kit of hardware and software parts to make LED art projects easier to build and better-looking, so sculptors and makers and multimedia artists can concentrate on building beautiful things instead of reinventing the wheel. I call it Fadecandy.
-

The Ardent Mobile Cloud Platform
This year I had the pleasure of working on a big art project for Burning Man with a wonderfully talented group of artists and engineers in my community. It started with a simple idea: Let’s bring a variable reach forklift to Burning Man, and put a cloud on it.
-

High Quality Zen
Announcing High Quality Zen, a batch renderer based on Zen photon garden. I built it as a way to further experiment with this 2D raytracing style, adding animation and color.
-

-

How we built a Super Nintendo out of a wireless keyboard
This is a guest article I wrote for Adafruit, on the story of how we built the hardware behind the new Sifteo Cubes, our second generation of a gaming platform that’s all about tactile sensation and real, physical objects.
-

S/PDIF Digital Audio on a Microcontroller
A few years ago, I implemented an S/PDIF encoder object for the Parallax Propeller. When I first wrote this object, I wrote only a very terse blog post on the subject. I rather like the simplicity and effectiveness of this project, so I thought I’d write a more detailed explanation for anyone who’s curious about…
-

Ramona Flowers subspace purse
I’m pretty new at this, and this was my biggest sewing project so far. The piping around the edges got kind of messed up in places, but overall I’m happy with the results. Front: Two layers of green denim with heavy interfacing Rear and sides: Two layers of green denim with medium interfacing Strap: Three…
-
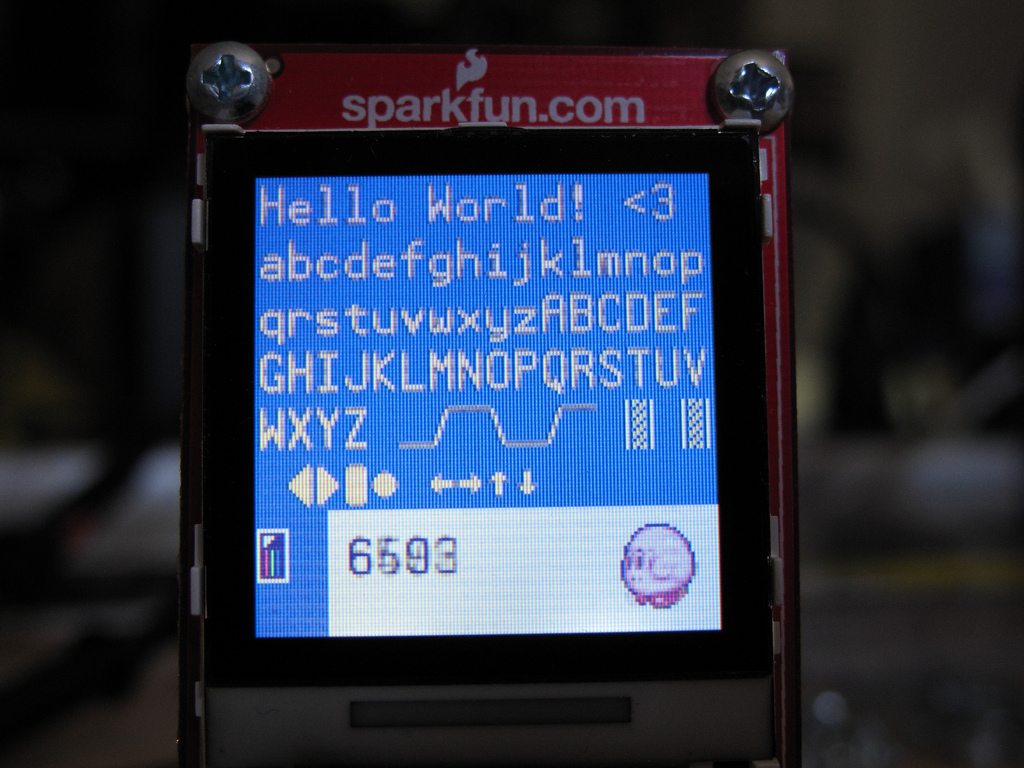
Sewing Machine Update: LCD
I had a rather cute 128×128 Nokia 6100 knockoff LCD that I wanted to use with the project. It’s inexpensive, not a bad quality/price tradeoff, and they’re pretty easy to interface with. Spark Fun already has plenty of drivers on their page for different microcontrollers. But of course, not a Propeller. And after searching through…
-

Embedded Bluetooth for $2
This is a continuation of my experiments in bit-banging full-speed USB on the Propeller. I have the basic host controller working reasonably well now, so I started trying to do something a bit more “useful” with it by implementing a simple Bluetooth stack on top of it. Bluetooth and USB are both quite complicated, and…
-

Hacking a Digital Bathroom Scale
People all around the internet have been doing cool things with the Wii peripherals lately, including the Wii Fit balance board. Things like controlling robots or playing World of Warcraft. But what if you just want one weight sensor, not four? The balance board starts to look kind of pricey, and who wants to deal…
-

DIY Sewing Machine Retrofit
The story behind this project is a bit overcomplicated. That’s all below, if you’re interested. I made a video to explain the final product: Back Story This all started when I bought a sewing machine for making fabric RFID tags a little over a year ago, and started using it to make cute plushy objects.…
-
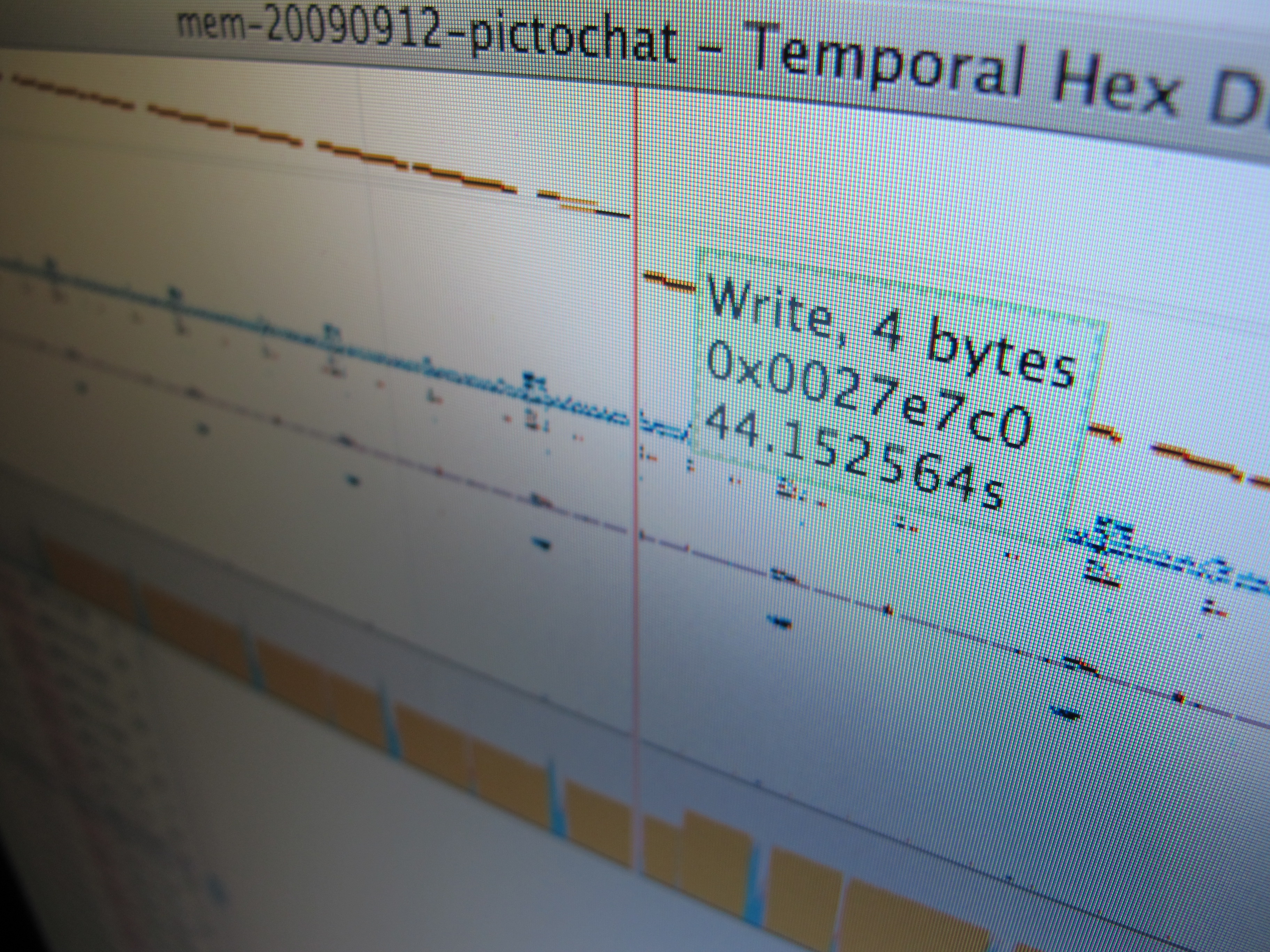
Temporal Hex Dump
After building some hardware to trace and inject data on the Nintendo DSi’s RAM bus, it became obvious pretty fast that there’s a lot of data there, and (as far as I know) no good tools for analyzing these sorts of logs. The RAM tracer has already given us a lot of insight into how…
-

DSi RAM tracing
It seems like a lot of people have been seeing my Flickr photostream and wondering what I must be up to- especially after my photos got linked on hackaday and reddit. Well, I’ve been meaning to write a detailed blog post explaining it all- but I keep running out of time. So I guess a…
-

Robot Odyssey DS: First screenshots
This is nowhere near ready for prime-time, but: Yep, it’s Robot Odyssey for the Nintendo DS. I literally just got this working yesterday, so please don’t ask for any precompiled binaries. If you don’t already know where the source code is, you really don’t want to see it 🙂 Before you ask, this is not…
-
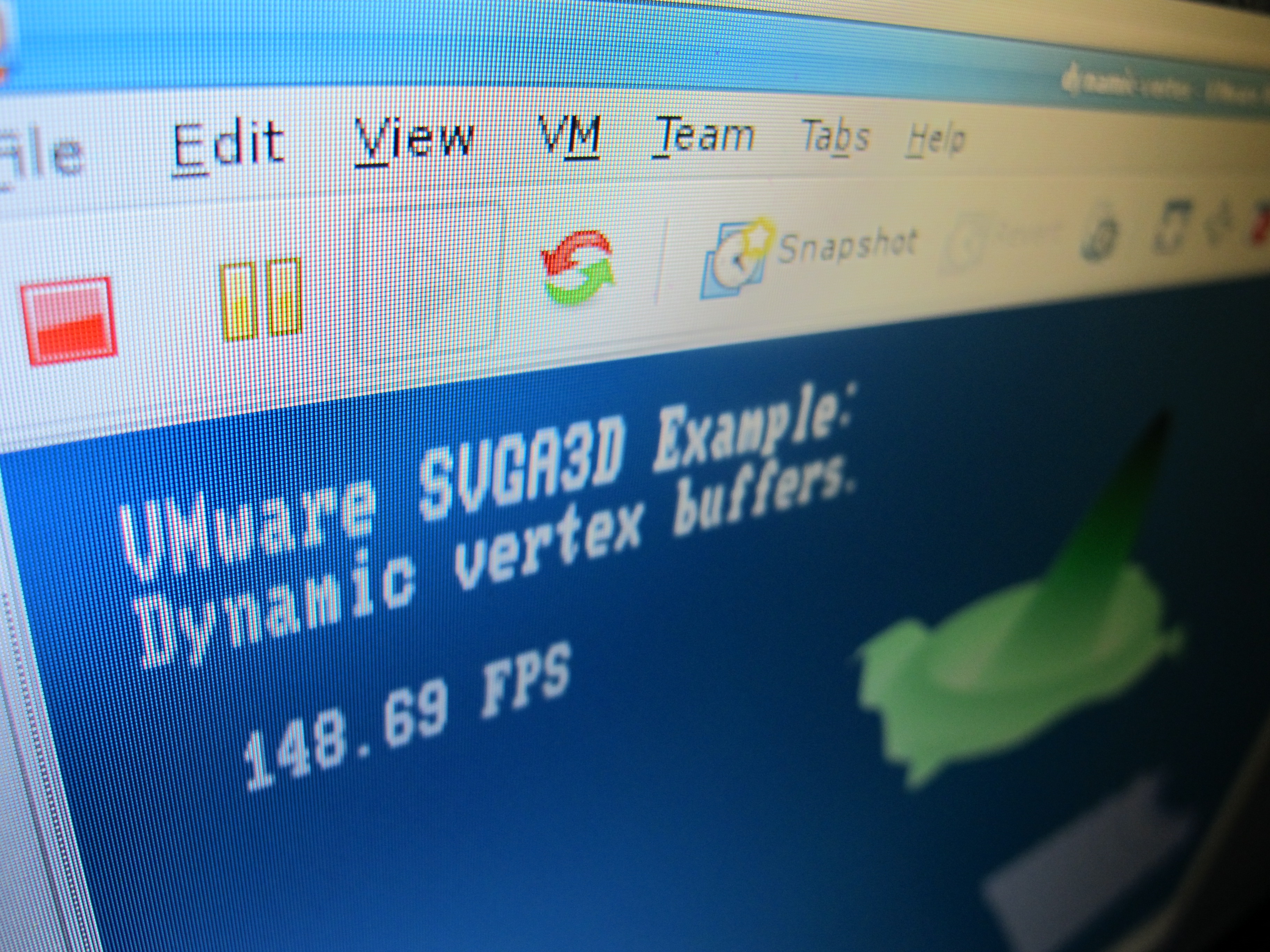
Announcing the VMware SVGA Device Developer Kit
Over the weekend, I finally had time to release another work-related open source project: the VMware SVGA Device Developer Kit. It’s a set of documentation and example code for the virtual graphics card that’s present in all VMware virtual machines. The examples run on the (virtual) bare metal, so it’s a really easy way to…
-
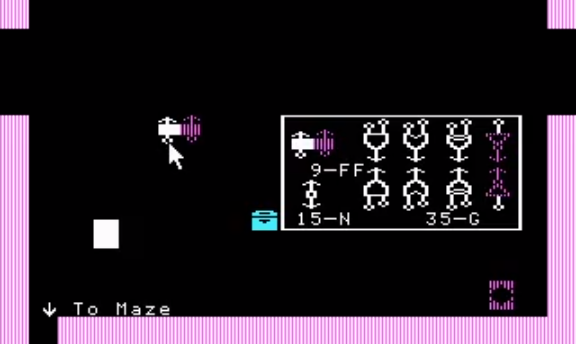
Robot Odyssey Mouse Hack 1
Yesterday I spent some more time reverse engineering Robot Odyssey. This was a great game, and it’s kind of a nostalgic pleasure for me to read and figure out all of this old 16-bit assembly. So far I’ve reverse engineered nearly all of the drawing code, big chunks of the world file format, and most…
-

Open source extra-sensitive high resolution TED receiver
Previously on the bloggy blog, I posted a few of my projects related to home data acquisition and to The Energy Detective (TED), a whole-house power measurement device. I made a set of homebrew wireless temperature sensors that display graphs on a digital picture frame, I reverse engineered the TED protocol, built a small self-contained…
-
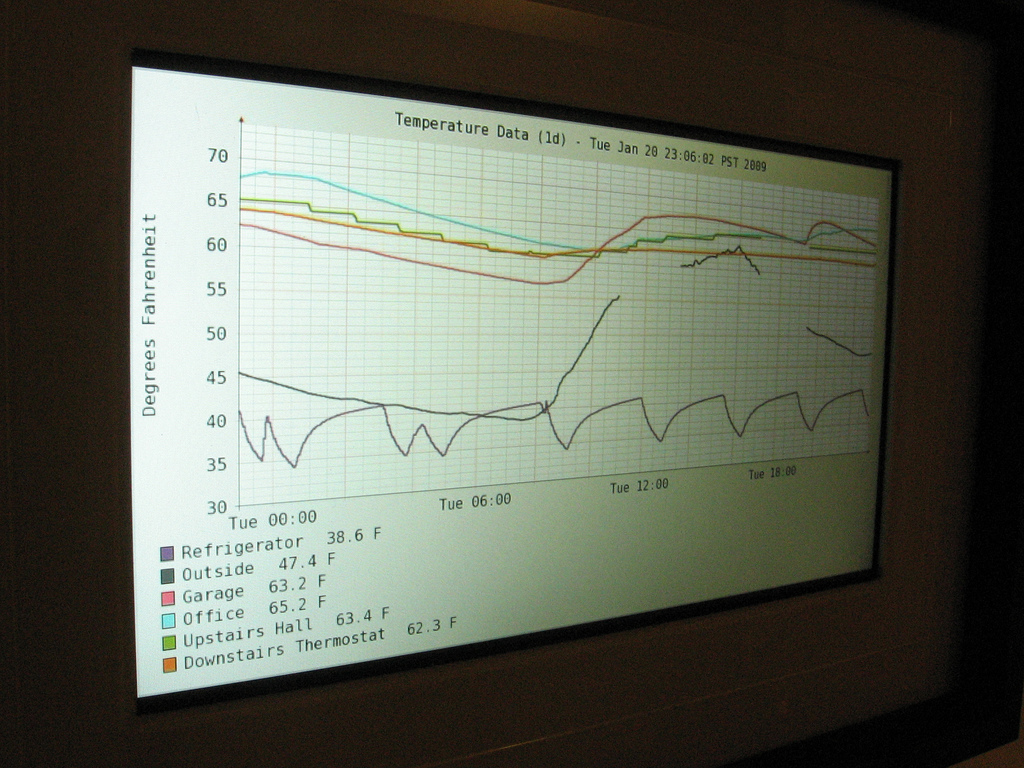
Wireless temperature picture frame mashup
This is the latest geeky addition to our home decor. It’s a Kodak W820 digital picture frame, showing a graph of real-time temperature data collected from around the house: upstairs and downstairs, garage, outdoors, and even inside the refrigerator. More photos on Flickr, implementation details below… Temperature Sensors Most of my friends probably know that…
-
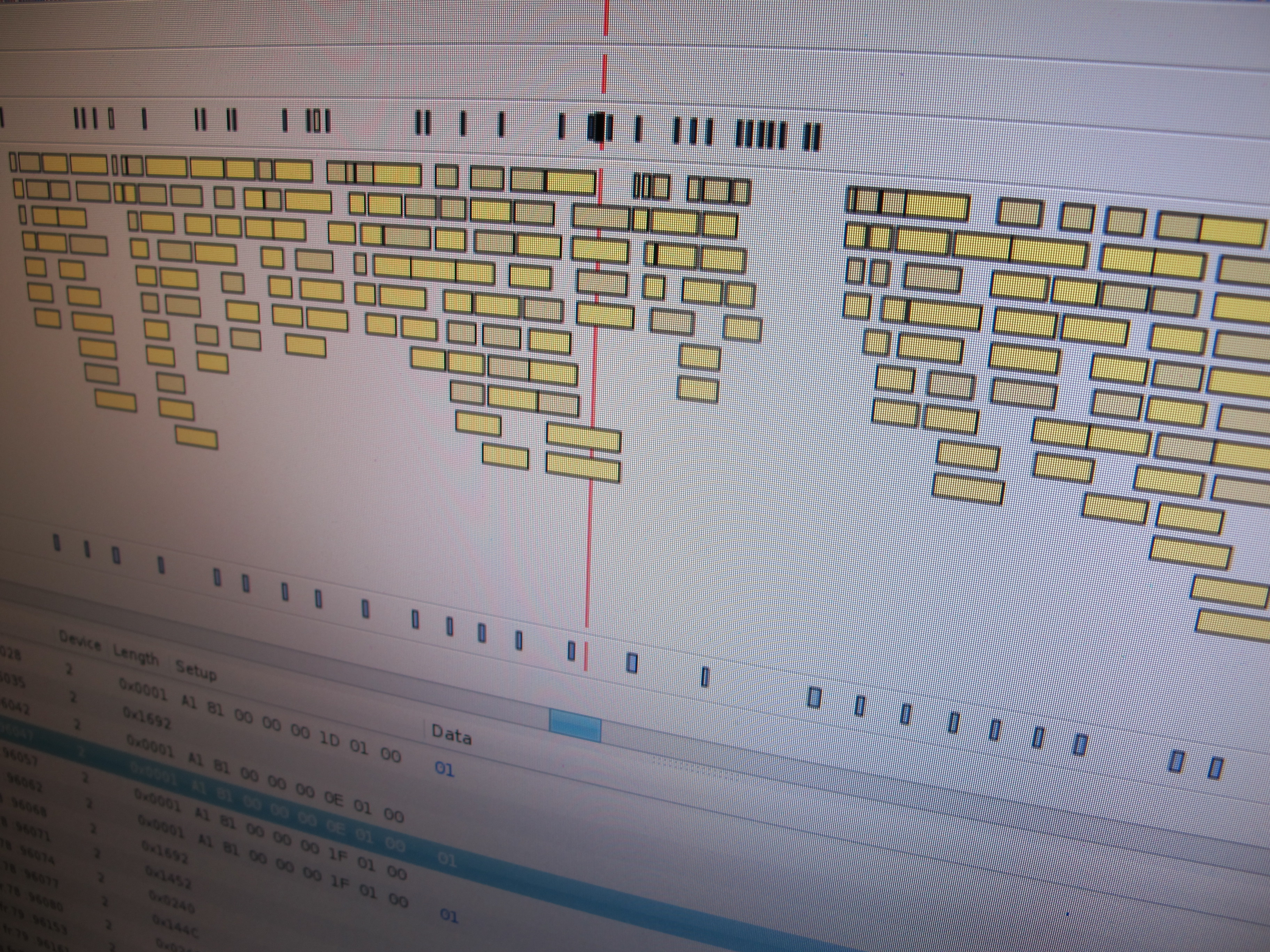
Virtual USB Analyzer
From late 2005 to early 2007, I worked on the USB virtualization stack at VMware. We ran into all sorts of gnarly bugs, many of which were very hard to reproduce or which required access to esoteric or expensive hardware. To help with debugging problems both internally and with customers in the field, we added…
-

GPU Virtualization at WIOV ’08
I just got back from the first USENIX Workshop on I/O Virtualization. WIOV was an interesting workshop. It was really nice to see what I/O virtualization looks like from a wide range of different viewpoints. There was some good industry perspective from AMD, Intel, Microsoft, and Oracle. There were also a wide range of academic…
-

The Kilowatt Clock
I thought I’d try putting together a YouTube video to show my latest crazy project. As usual, the schematic (navi-misc/tedrx/hardware/kwclock-v1-schematic.png) and firmware (navi-misc/tedrx/firmware/kwclock/main.c) is in Subversion.
-

Using an AVR as an RFID tag
Experiments in RFID, continued… Last time, I posted an ultra-simple “from scratch” RFID reader, which uses no application-specific components: just a Propeller microcontroller and a few passive components. This time, I tried the opposite: building an RFID tag using no application-specific parts. Well, my solution is full of dirty tricks, but the results aren’t half…
-

RFID Garage Door Opener
Today I finished a major update to my software-only RFID decoder for the Propeller microcontroller, and I finally installed my prototype in the garage. Now I can open the garage door with my RFID badge from work, while I’m on foot or on my bike 🙂 I’ll post some pictures once there’s some sunlight.
-

Simplest RFID reader?
That’s a Propeller microcontroller board with a few resistors and capacitors on it. Just add a coil of wire, and you have an RFID reader. Here’s a picture of it scanning my corporate ID badge, and displaying the badge’s 512 bits of content on a portable TV screen: If you’re into that sort of thing,…
-

Hard disk laser scanner at ILDA 4K
I should have blogged about this long ago, as I’ve been working on it off and on for about three months now, but today I reached an arbitrary milestone that compels me to post 😉 I’m still actively working on this project, so I’ll try to make updates occasionally, and if I end up putting…
-
3D Graphics at VMware
Despite all the random posts about helicopters and embedded systems on here, I haven’t really mentioned what I spend most of my time on these days… I work in the Interactive Devices group at VMware. For people who aren’t familiar with VMware’s products, we do virtualization: software that lets you run multiple virtual computers inside…
-

Playstation controller extender
The little hardware project I started almost 2 months ago is finally done. Completely finished. Bug free! Well, almost. It is, however, in a fully assembled state with firmware that is actually pretty usable. The Unicone2 is the result of my mini-quest to extend Playstation 2 controllers over long lengths of cat5 cable. A while…
-

Flightaware route histogram
Flightaware + Fyre: The above image is part of a histogram generated from Flightaware’s 24-hour time lapse. Click the link for the uncropped version. The original video is a Quicktime wrapper around individual PNG frames. I used mencoder to strip off the Quicktime wrapper, then a small Python script split the video streams into individual…
-

Life at 3.579545 MHz
Well, after an evening of cooking and hacking, I’ve managed to implement my own crazy software-only modulator for NTSC video. It can take an arbitrary JPEG image, turning it into an analog signal representing one field of color broadcast video. This analog signal happens to be playable by displaying a resulting image file on your…